快速开发神器,Spring-Data-Jpa初探
概述
最近一直在捣鼓spring boot,整体感受就是这玩意儿实在是太轻便了,去掉了各种繁琐的xml配置,就好像长期负重奔跑之后突然解掉了腿上的沙袋,写起代码来简直就像是在撒欢!
在尝试spring boot的过程中接触了一下曾经一直比较排斥的jpa(spring-data-jpa),然后整个人都被惊艳到了,那段时间脑子一直充满了各种“还写什么sql啊!!”、“还用什么mybatis啊”、”还建什么表啊!!“诸如此类balabala…
看过我的这些废话,各位看官应该也发现本文的主题了,没错,就是和spring-data-jpa相关。
其实spring-data-jpa已经出现了很久了,大约开始于spring 3.0,关于它的使用已经有很多很多文章、官方教程去介绍它,我就不重点介绍了。
咱们这篇文章的主旨是分析一下JPA中一个很让我惊艳的接口——JpaRepository的工作原理。
初探
在介绍它的原理之前,我们先来看两段代码:
UserInfo.java1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16@Entity
@Table(name = "t_u_user", uniqueConstraints = @UniqueConstraint(columnNames = "username"))
public class UserInfo extends BaseInfo {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column
protected long id;
@Column(length = 64, nullable = false)
private String username;
@Column(length = 64, nullable = false)
private String password;
/** getter and setters **/
}
UserDAO.java1
2
3
4
5
6
7
8
9@CacheConfig(cacheNames = "user:user")
public interface UserDAO extends JpaRepository<UserInfo, Long> {
@Cacheable(key = "'username:'+#p0")
UserInfo findByUsername(String username);
@CacheEvict(key = "'username:'+#p0.username")
<S extends UserInfo> S save(S entity);
}
在上面的代码中,UserInfo比较容易理解,它定义了一个实体对象,然后用注解的方式定义了对应的数据表。而第二段代码看起来仅仅是是定义了一个简单至极的DAO接口而已。
对于我们所熟悉的开发模式,以上代码只是一个写了一半的CRUD相关代码,但是对于spring jpa来说,它已经是一个完整的数据库操作的代码了,同时还使用Cache注解配置了UserInfo的缓存策略。
怎么样,是不是很惊讶!没有sql,没有xml,没有重复的insert、update、delete等等的代码,没有缓存操作的代码,你甚至可以连数据表都不用建,仅仅一个实体对象,一个接口和若干简单的注解,就完成了dao和缓存操作的开发,对于经常写写小应用的同学来说,简直是天大的福利!
有些同学可能要问了,JpaRepository接口仅仅是定义了一些固定的增删改查模板,如果我的查询是有条件的,还是得写个实现吧?然而并不是,spring jpa的特性可以让你大部分的有“条件”的操作(如查询)都不用写具体的实现,只需要在方法名中定义即可。比如上面的接口中我们定义了一个方法findByUsername,它的作用顾名思义,就是通过username这个字符串去数据库查询一个UserInfo对象,整个过程我们只需要一个方法,根本不需要实现(Ma~gic~~~)。
OK,了解了Jpa怎么使用,现在我们来看看对应的配置。
同使用起来一样,其对应的配置也非常简单,如果是最基础的配置,只需要在application.properties里配置一下数据源。
这里附带一个application.properties的完整配置以供参考1
2
3
4spring.datasource.url=jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
整个数据库相关开发流程就完成了,是不是特别简单?更多spring jpa的特性请参见官方文档
工作原理
看了上面的例子,大家一定会被JpaRepository这个神奇的接口所吸引吧,那么现在就回归的本文的重点,我们去探寻一下JpaRepository的工作原理,看看spring是如何实现这种“神奇”的效果的。
首先,当然是debug看一下spring会为我们上面定义的接口注入一个什么样的实现。编写如下test case1
2
3
4
5
6
7
8
9
10
11
12
13@Autowired
private UserDAO userDAO;
@Test
@Transactional
public void userDAOTest() {
UserInfo userInfo = new UserInfo();
userInfo.setUsername("lalala");
userInfo.setPassword("lululu");
userDAO.save(userInfo);
UserInfo result = userDAO.findByUsername(userInfo.getUsername());
System.out.println(result);
}
debug的结果如下
通过Debug我们可以看到userDAO被注入了一个动态代理,被代理的类是JpaRepository的一个实现SimpleJpaRespositry,InvocationHandler是JdkDynamicAopProxy,好像看到这些信息突然什么都懂了呢!但是作为一个好奇宝宝,此时非常想知道这玩意儿到底是怎么注入进去的,于是就开始了各种debug+看源码的过程,同时为了能比较清楚的理一下这个链路,我决定画一下整个注入链路的时序图,先从bean的加载开始吧!
(五个小时过去了……画完下面这个玩意儿的我除了对自己满满的吐槽之外什么话都不想说,如果一定要说点什么,那只能是图样图森破了!naive!画完之后好长一段时间整个人都是懵逼的,本来是想画个图来给大家理理思路的,但是现在…希望你不会被绕晕)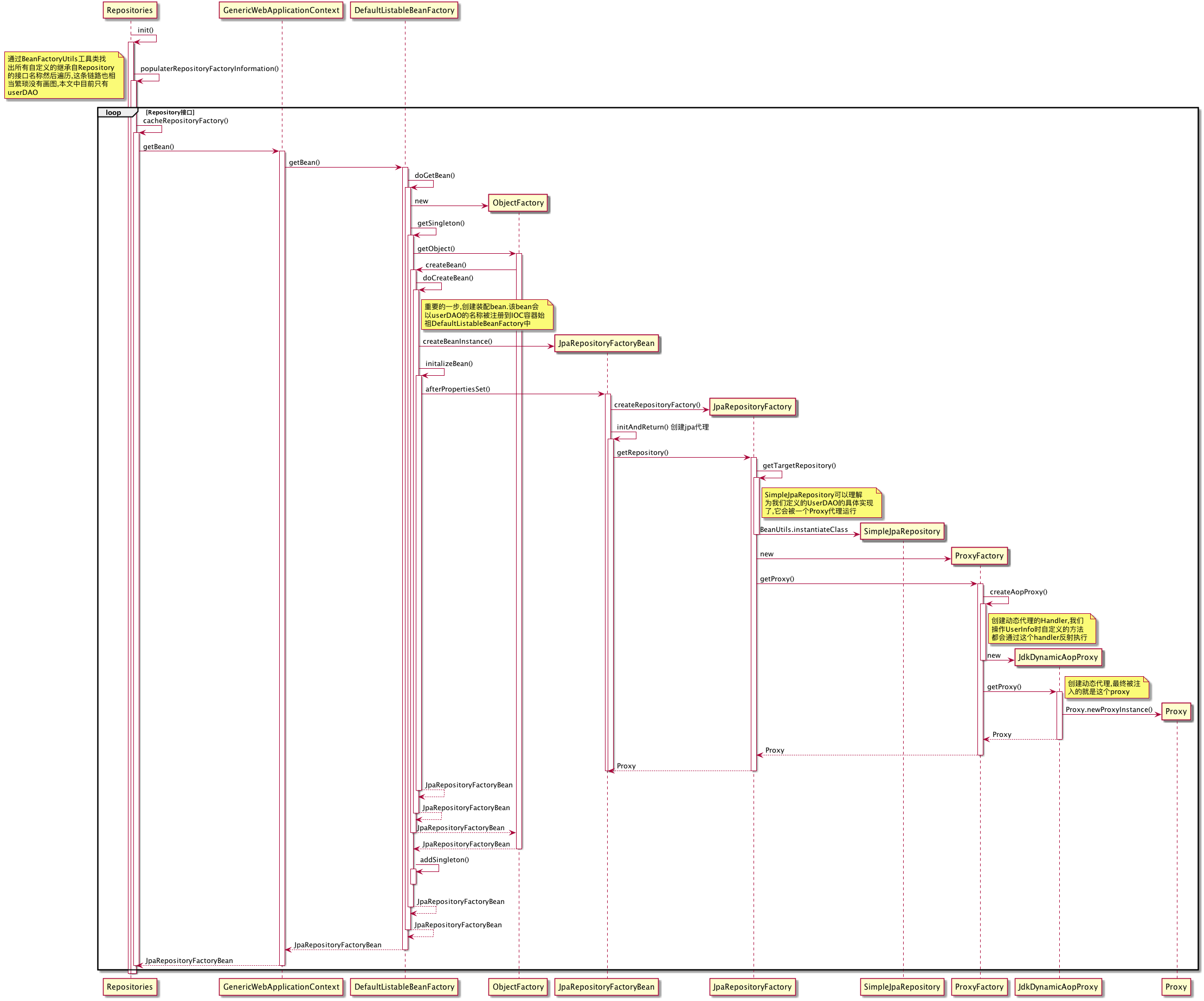
整个时序图如上,没有分模块画,因为理清楚模块估计要好几个“五小时”了,时间仓促。简单总结如下:
spring在启动的时候会实例化一个Repositories,它会去扫描所有的class,然后找出由我们定义的、继承自org.springframework.data.repository.Repository的接口,然后遍历这些接口,针对每个接口依次创建如下几个实例:
- SimpleJpaRespositry——用来进行默认的DAO操作,是所有Repository的默认实现
- JpaRepositoryFactoryBean——装配bean,装载了动态代理Proxy,会以对应的DAO的beanName为key注册到DefaultListableBeanFactory中,在需要被注入的时候从这个bean中取出对应的动态代理Proxy注入给DAO
- JdkDynamicAopProxy——动态代理对应的InvocationHandler,负责拦截DAO接口的所有的方法调用,然后做相应处理,比如findByUsername被调用的时候会先经过这个类的invoke方法
以上就是整个Bean加载链路的简单描述。扫描的过滤条件和过程也非常繁琐,等以后找时间再捋一遍吧。
搞清楚了接口对应的实现是什么,怎么来的,接下来就要看看它是怎么工作的了。继续往下debug,在进到findByUsername方法的时候,发现被上文提到的JdkDynamicAopProxy捕获,然后经过一系列的方法拦截,最终进到QueryExecutorMethodInterceptor.doInvoke中,QueryExecutorMethodInterceptor是哪里来的呢?跟踪一下会发现,这个Interceptor就是上图对应的JpaRepositoryFactory的内部类,它是在“加载链路”的JpaRepositoryFactoryBean.getRepository()被调用时设置进去的,doInvoke的代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20private Object doInvoke(MethodInvocation invocation) throws Throwable {
Method method = invocation.getMethod();
Object[] arguments = invocation.getArguments();
if (isCustomMethodInvocation(invocation)) {
Method actualMethod = repositoryInformation.getTargetClassMethod(method);
return executeMethodOn(customImplementation, actualMethod, arguments);
}
if (hasQueryFor(method)) {
return queries.get(method).execute(arguments);
}
// Lookup actual method as it might be redeclared in the interface
// and we have to use the repository instance nevertheless
Method actualMethod = repositoryInformation.getTargetClassMethod(method);
return executeMethodOn(target, actualMethod, arguments);
}
这个拦截器主要做的事情就是判断方法类型,然后执行对应的操作:
- 如果是开发者自定义的实现类中的方法,则调用其实现类中的对应方法
- 如果是自定义查询,则从查询集合中取得对应的查询策略,然后根据参数构造查询语句进行查询
- 否则,调用默认实现SimpleJpaRespositry中的方法。
我们的findByUsername属于自定义查询,于是就进入了查询策略对应的execute方法。在执行execute时,会先选取对应的JpaQueryExecution1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17protected JpaQueryExecution getExecution() {
if (method.isStreamQuery()) {
return new StreamExecution();
} else if (method.isProcedureQuery()) {
return new ProcedureExecution();
} else if (method.isCollectionQuery()) {
return new CollectionExecution();
} else if (method.isSliceQuery()) {
return new SlicedExecution(method.getParameters());
} else if (method.isPageQuery()) {
return new PagedExecution(method.getParameters());
} else if (method.isModifyingQuery()) {
return method.getClearAutomatically() ? new ModifyingExecution(method, em) : new ModifyingExecution(method, null);
} else {
return new SingleEntityExecution();
}
}
如上述代码所示,它会根据方法的一系列条件——返回值类型、注解、参数等等来判断它应该使用哪一个JpaQueryExecution,有流式查询(JAVA8特性)、存储过程、批量查询等等,我们的findByUsername最终落入了SingleEntityExecution——返回单个实例的Execution(好想吐槽这种每get一下都会new的设计)。继续跟踪他的execute方法,最终找到了拼装sql的类CriteriaQueryImpl,具体的拼装代码有些长,本文就不贴了,具体的内容可以看CriteriaQueryImpl.interpret(),其实就是根据一个“已经装配好的条件类”进行各种判断然后拼接字符串。你可能已经注意到了我前面提到的“已经装配好的条件类”,在这个时候拿到的这个条件类是将查询字段username以及查询结果类型UserInfo全部获取到的,也就是说在这一步的时候,spring已经知道查询条件是username了,那么问题来了,spring是在什么时候知道我们的查询条件是username的呢?是取自方法名中的ByUsername还是方法参数username呢?
带着以上问题继续跟代码,我们发现还是在最初的Bean加载链路时,还是在JpaRepositoryFactoryBean.getRepository()方法被调用的过程中,还是在实例化QueryExecutorMethodInterceptor这个拦截器的时候,spring会去为我们的方法创建一个PartTreeJpaQuery,在它的构造方法中同时会实例化一个PartTree对象,代码如下
1 | public class PartTree implements Iterable<OrPart> { |
看到了这个PartTree,所有迷雾都被解开了,它定义了一系列的正则表达式,全部用于截取方法名,通过方法名来分解查询的条件,排序方式,查询结果等等,这个分解的步骤是在进程启动时加载Bean的过程中进行的,当执行查询的时候直接取方法对应的PartTree用来进行sql的拼装,然后进行DB的查询,返回结果。
到此为止,我们整个JpaRepository接口相关的链路就算走通啦,简单的总结如下:
spring会在启动的时候扫描所有继承自Repository接口的DAO接口,然后为其实例化一个动态代理,同时根据它的方法名、参数等为其装配一系列DB操作组件,在需要注入的时候为对应的接口注入这个动态代理,在DAO方法被调用的时会走这个动态代理,然后经过一系列的方法拦截路由到最终的DB操作执行器JpaQueryExecution,然后拼装sql,执行相关操作,返回结果。
以上是本文的全部内容,本人也刚接触JPA不久,文中有误的地方欢迎大家提出来我会及时修改,以免误导别人。最近一直在捣鼓spring boot,spring cloud这种东西,如有同好欢迎一起探讨学习!